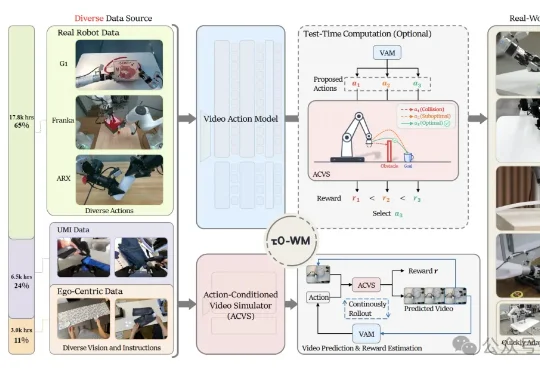
τ0-WM:最大规模预训练的开源具身世界模型来了
τ0-WM:最大规模预训练的开源具身世界模型来了刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。
来自主题: AI技术研报
9169 点击 2026-05-31 19:39
 搜索
搜索
刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。

即将结束博士生涯的童晟邦,正站在另一个起点上。

刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。

世界模型(World Model),想必你已经在很多场合听过这个术语了。它有时出现在视频生成领域,有时又出现在具身智能领域;它们的含义还有所差别,甚至看起来像是完全不同的概念。

为了理清视觉与世界模型之间的深层联系,并为该领域的未来研究提供一张清晰的脉络图,北京交通大学靳潇杰、魏云超、赵耀等学者联合新加坡国立大学、腾讯、字节等国内外研究机构知名学者,发布了首篇视觉世界模型长篇综述:From Seeing to Knowing the World: A Survey of Vision World Models。
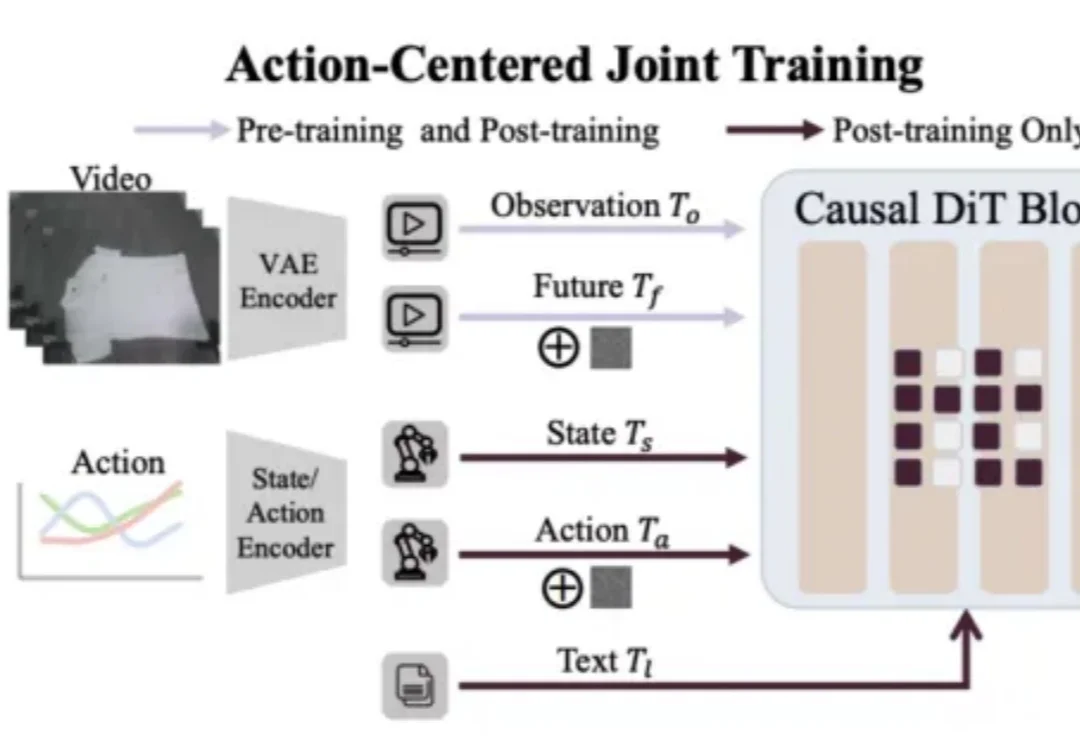
最近,具身智能圈被 Generalist CEO 的一篇长文《Going Beyond World Models & VLAs》刷屏。文章抛出了一个看似振聋发聩的观点:目标远比工具标签更重要。与其陷入 “我们到底是在做 VLA(视觉 - 语言 - 动作模型)还是世界模型(World Model)” 的教条之争,不如回归本源:让机器高效、准确地作用于物理世界。
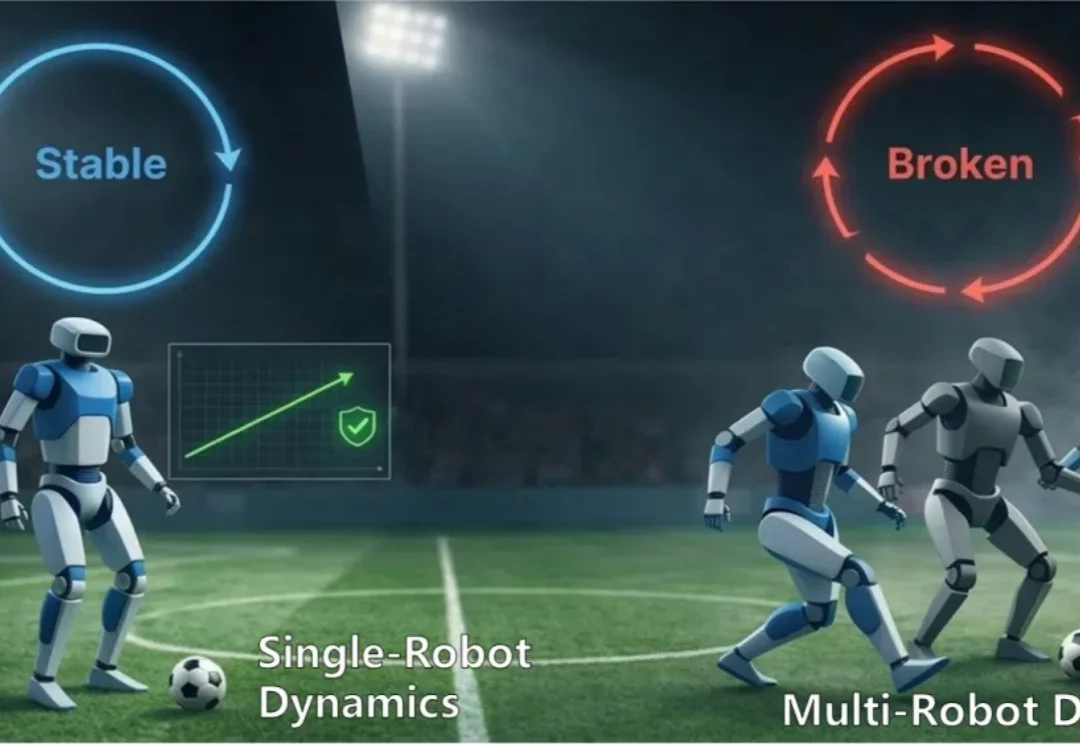
近年来,Decision-Coupled World Model 与 Model-based RL 在机器人领域取得了显著成功。通过学习环境动力学模型,智能体能够在内部模拟未来,从而进行规划与决策。但当系统从单机器人扩展到多机器人时,问题开始变得棘手。
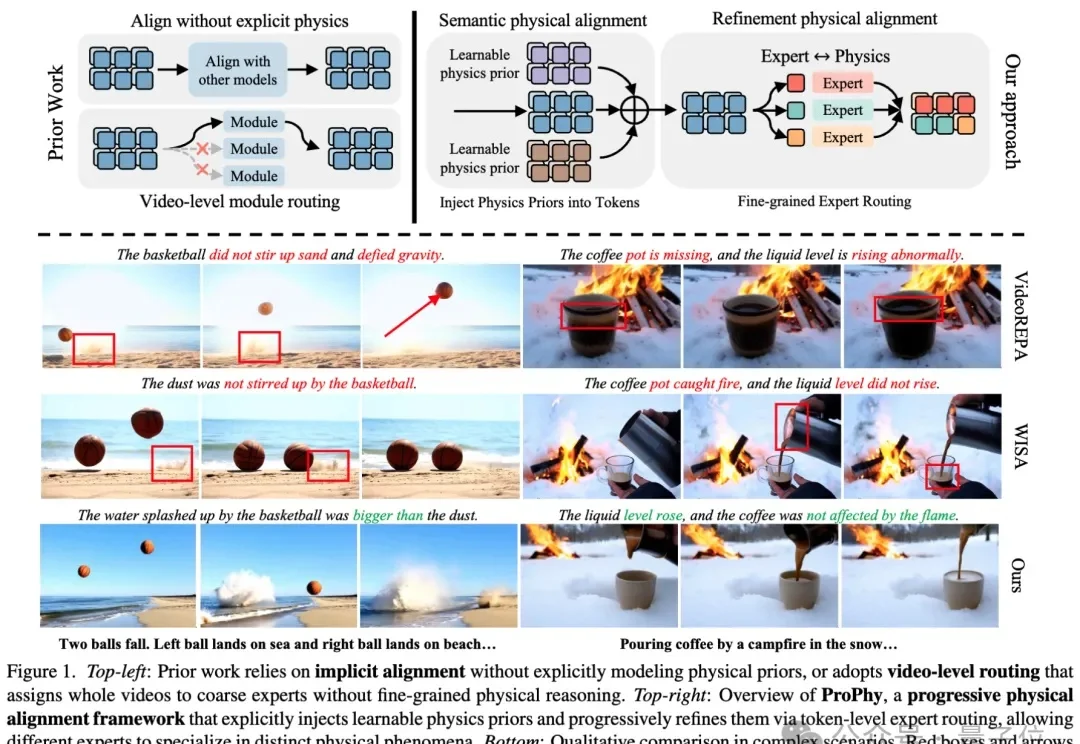
当人们谈到“世界模型”(World Models)时,很多人会首先想到近年来迅速发展的生成式视频模型。
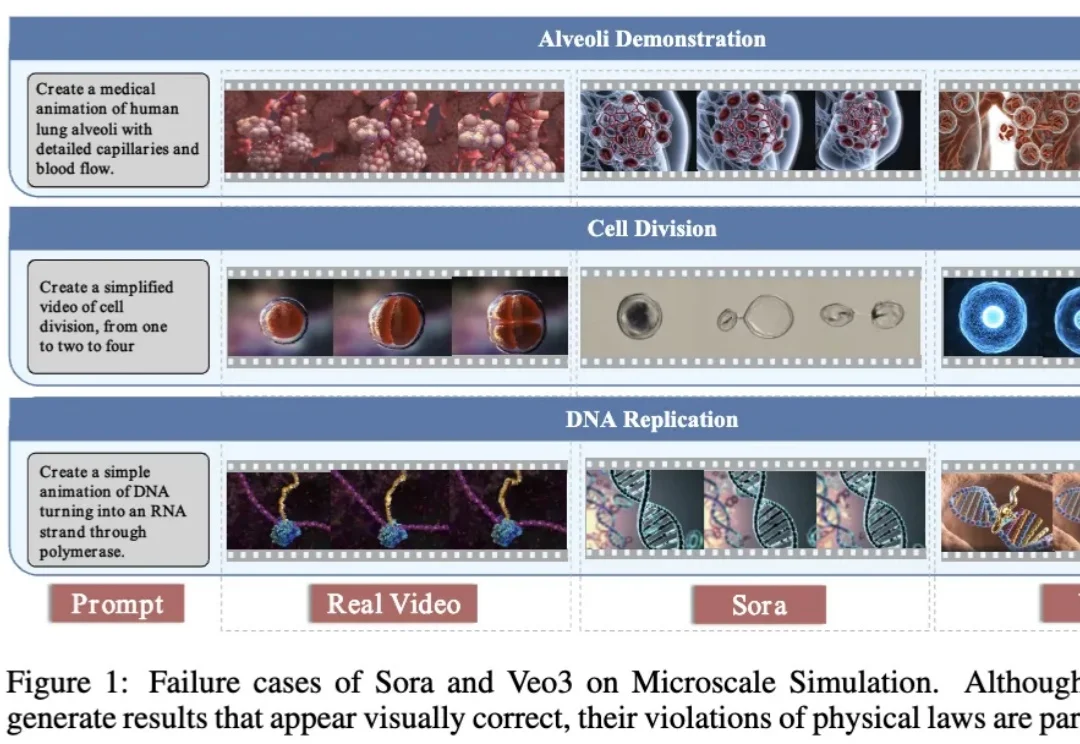
过去两年,世界模型(World Model)正在成为大模型演进的重要方向。
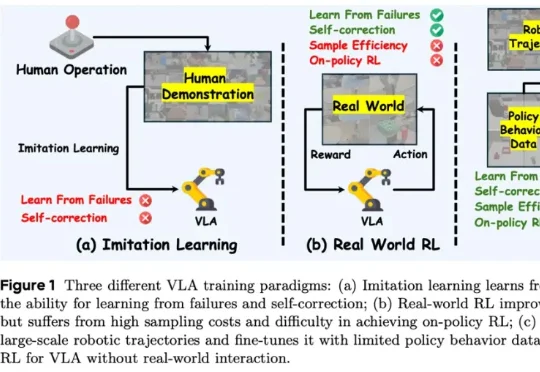
香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。